传送门:http://acm.hdu.edu.cn/showproblem.php?pid=6470
题意
$已知f(1) = 1, f(2) =2,且f(n)=f(n-1)+2f(n-2)+n^3\;\;(mod\;\;1234567789)$
思路
对于线性递推,仿照快速幂,我们可以用矩阵快速幂优化(这就是线代吗?爱了爱了)。
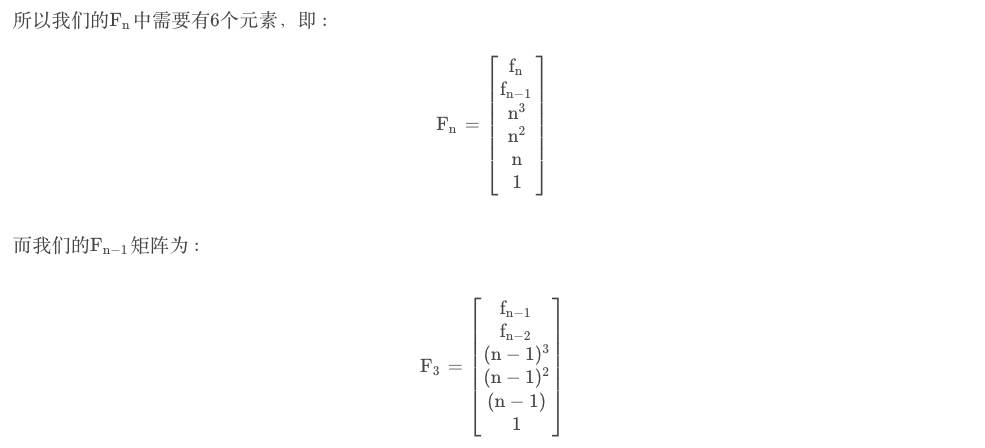
考虑F_n为第n个矩阵,那就需要构造新的“递推矩阵”。
因为递推中有个$f_n$中$n^3$,所以$f_{n-1}$中需要有$(n-1)^3$,结合二项式定理可得:
$$n^3=[(n-1)+1]^3=C_{3}^0(n-1)^3+C_3^1(n-1)^2+C_{3}^2(n-1)^1+C_3^3(n-1)^0$$

所以说线性递推可以用矩阵快速幂优化。
但是!最近被mod坑死了,如果在矩阵乘法中每次都用mod,大概最高会有4秒,但是先判断在mod的话只有两秒,足足差了2秒!!!模运算是真的太慢了。。。
Code (967MS)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
| ##include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef long double ld;
typedef pair<int, int> pdd;
##define INF 0x3f3f3f3f
##define lc u << 1
##define rc u << 1 1
##define mm (l + r) / 2
##define mid (t[u].l + t[u].r) / 2
##define lowbit(x) x & (-x)
##define mem(a, b) memset(a , b , sizeof(a))
##define FOR(i, x, n) for(int i = x;i <= n; i++)
ll mod = 123456789;
struct Martix{
ll m[6][6];
};
Martix ans;
Martix E;
Martix operator * (Martix a, Martix b) {
Martix c;
mem(c.m, 0);
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
for (int k = 0; k < 6; k++) {
c.m[i][j] = (c.m[i][j] + a.m[i][k] * b.m[k][j]);
if(c.m[i][j] > mod)
c.m[i][j] %= mod;
}
}
}
return c;
}
Martix quick_pow_Martix(ll n) {
Martix base = E;
mem(ans.m, 0);
ans.m[0][0] = 2;
ans.m[1][0] = 1;
ans.m[2][0] = 8;
ans.m[3][0] = 4;
ans.m[4][0] = 2;
ans.m[5][0] = 1;
while(n) {
if(n & 1)
ans = base * ans;
base = base * base;
n >>= 1;
}
return ans;
}
void solve() {
E.m[0][0] = 1; E.m[0][1] = 2; E.m[0][2] = 1; E.m[0][3] = 3; E.m[0][4] = 3; E.m[0][5] = 1;
E.m[1][0] = 1;
E.m[2][2] = 1; E.m[2][3] = 3; E.m[2][4] = 3; E.m[2][5] = 1;
E.m[3][3] = 1; E.m[3][4] = 2; E.m[3][5] = 1;
E.m[4][4] = 1; E.m[4][5] = 1;
E.m[5][5] = 1;
int T;
scanf("%d",&T);
while(T--) {
ll n;
scanf("%lld",&n);
printf("%lld\n",quick_pow_Martix(n - 2).m[0][0]);
}
}
signed main() {
ios_base::sync_with_stdio(false);
##ifdef FZT_ACM_LOCAL
freopen("in.txt", "r", stdin);
freopen("out.txt", "w", stdout);
signed test_index_for_debug = 1;
char acm_local_for_debug = 0;
do {
if (acm_local_for_debug == '$') exit(0);
if (test_index_for_debug > 20)
throw runtime_error("Check the stdin!!!");
auto start_clock_for_debug = clock();
solve();
auto end_clock_for_debug = clock();
cout << "Test " << test_index_for_debug << " successful" << endl;
cerr << "Test " << test_index_for_debug++ << " Run Time: "
<< double(end_clock_for_debug - start_clock_for_debug) / CLOCKS_PER_SEC << "s" << endl;
cout << "--------------------------------------------------" << endl;
} while (cin >> acm_local_for_debug && cin.putback(acm_local_for_debug));
##else
solve();
##endif
return 0;
}
|
本文作者:jujimeizuo
本文地址: https://blog.jujimeizuo.cn/2020/10/30/hdu-6470/
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0 协议。转载请注明出处!